Bug #13462
Memory erasure on boot medium removal is fragile
0%
Description
Happened 14 times in June, 23 for what 2017 logs we have.
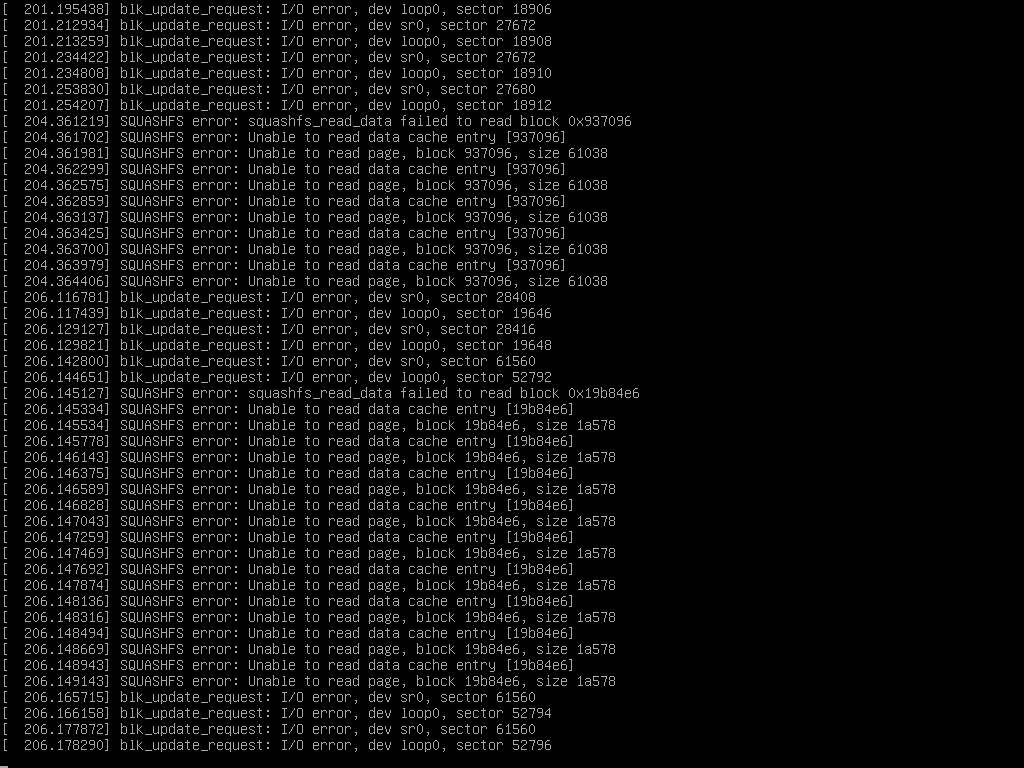
SQUASHFS reading error. Some data are missing in memory for the shutdown.
Happens only in the scenarios with vfat or LUKS-encrypted ext4 variants.
Files
{kind=link}
Subtasks
Related issues
|
Related to Tails - |
Resolved | 2017-06-05 | 2017-07-05 |
|
Blocks Tails - |
Resolved | 2017-06-29 | |
| Blocks Tails - Feature #16209: Core work: Foundations Team | Confirmed |
History
#1 Updated by bertagaz 2017-07-12 12:39:37
- File 01_40_27_Tails_erases_memory_on_DVD_boot_medium_removal__LUKS-encrypted_ext4.png added
- Feature Branch set to bugfix/13462-vfat-LUKS-ext4-emergency-shutdown-scenarios-are-fragile
#2 Updated by bertagaz 2017-07-12 12:39:52
- related to
Feature #12289: Deal with June 2017 false positive scenarios added
#3 Updated by bertagaz 2017-07-12 13:42:44
- Status changed from Confirmed to In Progress
Applied in changeset commit:762fe238ff9f429f8d01b8449628f10063e58e37.
#4 Updated by intrigeri 2017-07-13 18:32:24
- Assignee changed from anonym to bertagaz
- QA Check set to Info Needed
> SQUASHFS reading error. Some data are missing in memory for the shutdown.
Wait, this seems to be a real bug in Tails identified by our test suite. So why should we handle this as a false positive?
#5 Updated by bertagaz 2017-07-14 09:55:43
- Assignee changed from bertagaz to intrigeri
intrigeri wrote:
> > SQUASHFS reading error. Some data are missing in memory for the shutdown.
>
> Wait, this seems to be a real bug in Tails identified by our test suite. So why should we handle this as a false positive?
That’s right. I did not think about that in the rush of dealing with the amount of test failures. Not sure of the next step.
#6 Updated by bertagaz 2017-07-14 09:56:02
- Parent task deleted (
Bug #10288)
#7 Updated by intrigeri 2017-07-17 08:25:34
- QA Check deleted (
Info Needed)
#8 Updated by intrigeri 2017-07-17 08:25:44
- Target version changed from Tails_3.2 to Tails_3.1
#9 Updated by intrigeri 2017-07-17 08:25:58
- blocks
Feature #13234: Core work 2017Q3: Foundations Team added
#10 Updated by intrigeri 2017-07-22 12:24:49
- Assignee changed from intrigeri to bertagaz
- QA Check set to Info Needed
bertagaz wrote:
> That’s right. I did not think about that in the rush of dealing with the amount of test failures. Not sure of the next step.
Next steps are reverting the bogus false positive classification (I did it myself in commit:c2e7b24364e662b05ea485f026ca6786863dbc03) and then investigate, which I’ll do with my Foundations Team hat once I am pointed to the relevant tech details.
Please point me to the debug log & videos, or to a test suite run that exposed this problem. I’ve tried to find one based on artifacts file name and failed. If it’s too late to find this info, well, too bad: then let me know ASAP and I’ll investigate via other means. Please remember to attach such info next time, so it’s easier to handle the output of your triaging session :)
#11 Updated by bertagaz 2017-07-27 16:39:52
intrigeri wrote:
> bertagaz wrote:
> > That’s right. I did not think about that in the rush of dealing with the amount of test failures. Not sure of the next step.
>
> Next steps are reverting the bogus false positive classification (I did it myself in commit:c2e7b24364e662b05ea485f026ca6786863dbc03) and then investigate, which I’ll do with my Foundations Team hat once I am pointed to the relevant tech details.
>
> Please point me to the debug log & videos, or to a test suite run that exposed this problem. I’ve tried to find one based on artifacts file name and failed. If it’s too late to find this info, well, too bad: then let me know ASAP and I’ll investigate via other means. Please remember to attach such info next time, so it’s easier to handle the output of your triaging session :)
I did for other failures, but did not think about it for this one. You can find such a failure there: https://jenkins.tails.boum.org/job/test_Tails_ISO_devel/905/
If you have a look at the test history of the stable or devel branch in Jenkins, some failing runs (in June) are marked with this ticket.
#12 Updated by bertagaz 2017-07-27 16:40:28
- Assignee changed from bertagaz to intrigeri
- QA Check changed from Info Needed to Dev Needed
#13 Updated by intrigeri 2017-07-27 17:00:16
Thanks!
#14 Updated by intrigeri 2017-07-27 18:22:00
Debug log:
Scenario: Tails erases memory on DVD boot medium removal: LUKS-encrypted ext4 # features/emergency_shutdown.feature:33
01:41:36.439764363: calling as root: echo 'hello?'
01:41:36.732403418: call returned: [0, "hello?\n", ""]
01:41:37.464959192: [log] CLICK on L(1023,384)@S(0)[0,0 1024x768]
01:41:37.465335517: calling as root: nmcli device show eth0
01:41:37.831085794: call returned: [0, "GENERAL.DEVICE: eth0\nGENERAL.TYPE: ethernet\nGENERAL.HWADDR: 50:54:00:EB:76:C4\nGENERAL.MTU: 1500\nGENERAL.STATE: 20 (unavailable)\nGENERAL.CONNECTION: --\nGENERAL.CON-PATH: --\nWIRED-PROPERTIES.CARRIER: off\n", ""]
01:41:37.854498835: calling as root: date -s '@1498298063'
01:41:38.162713309: call returned: [0, "Sat Jun 24 09:54:23 UTC 2017\n", ""]
Given I have started Tails from DVD without network and logged in # features/step_definitions/snapshots.rb:172
01:41:38.164127328: calling as root: free -m | awk '/^Mem:/ { print $2 }'
01:41:38.456137405: call returned: [0, "2004\n", ""]
01:41:38.456420194: calling as root: echo 3 > /proc/sys/vm/drop_caches
01:41:39.048788533: call returned: [0, "", ""]
01:41:39.048974399: calling as root: touch /run/initramfs/tails_shutdown_debugging
01:41:40.881714718: call returned: [0, "", ""]
01:41:40.881988489: calling as root: sysctl vm.oom_kill_allocating_task=0
01:41:41.228696415: call returned: [0, "vm.oom_kill_allocating_task = 0\n", ""]
01:41:41.228923382: calling as root: sysctl vm.oom_dump_tasks=0
01:41:41.407106191: call returned: [0, "vm.oom_dump_tasks = 0\n", ""]
01:41:41.407320320: calling as root: sysctl vm.overcommit_memory=0
01:41:41.681432599: call returned: [0, "vm.overcommit_memory = 0\n", ""]
01:41:41.681679567: calling as root: sysctl vm.min_free_kbytes=65536
01:41:41.891262884: call returned: [0, "vm.min_free_kbytes = 65536\n", ""]
01:41:41.891481820: calling as root: sysctl vm.admin_reserve_kbytes=131072
01:41:42.098152649: call returned: [0, "vm.admin_reserve_kbytes = 131072\n", ""]
01:41:42.098373479: calling as root: free -m | awk '/^Mem:/ { print $3 }'
01:41:42.469530663: call returned: [0, "546\n", ""]
01:41:42.469697180: calling as root: systemctl status initramfs-shutdown.service
01:41:42.783075745: call returned: [0, "● initramfs-shutdown.service - Prepare /run/initramfs for shutdown\n Loaded: loaded (/lib/systemd/system/initramfs-shutdown.service; enabled; vendor preset: enabled)\n Active: active (exited) since Sat 2017-06-24 08:26:58 UTC; 1h 27min ago\n Docs: https://tails.boum.org/contribute/design/memory_erasure/\n Main PID: 3673 (code=exited, status=0/SUCCESS)\n Tasks: 0 (limit: 4915)\n CGroup: /system.slice/initramfs-shutdown.service\n\nJun 24 08:26:48 localhost.localdomain systemd[1]: Starting Prepare /run/initramfs for shutdown...\nJun 24 08:26:58 localhost.localdomain systemd[1]: Started Prepare /run/initramfs for shutdown.\n", ""]
01:41:42.783231200: calling as root: systemctl status memlockd.service
01:41:43.157998690: call returned: [0, "● memlockd.service - memlockd\n Loaded: loaded (/lib/systemd/system/memlockd.service; enabled; vendor preset: enabled)\n Drop-In: /lib/systemd/system/memlockd.service.d\n └─oom.conf\n Active: active (running) since Sat 2017-06-24 08:26:48 UTC; 1h 27min ago\n Main PID: 3675 (memlockd)\n Tasks: 1 (limit: 4915)\n CGroup: /system.slice/memlockd.service\n └─3675 /usr/sbin/memlockd -f -u memlockd\n\nJun 24 08:26:49 localhost.localdomain memlockd[3675]: Mapped file /bin/rm\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /bin/sh\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /bin/sleep\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /bin/systemctl\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /lib/systemd/system-shutdown/tails\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /lib/systemd/systemd-shutdown\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /usr/bin/eject\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /usr/bin/pkill\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /usr/local/sbin/udev-watchdog\nJun 24 08:26:50 localhost.localdomain memlockd[3675]: Mapped file /lib/x86_64-linux-gnu/libudev.so.1\n", ""]
01:41:43.158188281: calling as root: systemctl status tails-shutdown-on-media-removal.service
01:41:43.463759472: call returned: [0, "● tails-shutdown-on-media-removal.service - Wipe memory on live media removal\n Loaded: loaded (/lib/systemd/system/tails-shutdown-on-media-removal.service; enabled; vendor preset: enabled)\n Active: active (running) since Sat 2017-06-24 08:26:48 UTC; 1h 27min ago\n Docs: https://tails.boum.org/contribute/design/memory_erasure/\n Main PID: 3689 (udev-watchdog-w)\n Tasks: 2 (limit: 4915)\n CGroup: /system.slice/tails-shutdown-on-media-removal.service\n ├─3689 /bin/sh /usr/local/lib/udev-watchdog-wrapper\n └─3778 /usr/local/sbin/udev-watchdog /devices/pci0000:00/0000:00:1f.2/ata3/host2/target2:0:0/2:0:0:0/block/sr0 cd\n\nJun 24 08:26:48 localhost.localdomain systemd[1]: Started Wipe memory on live media removal.\n", ""]
And I prepare Tails for memory erasure tests # features/step_definitions/erase_memory.rb:57
01:41:43.507524898: libguestfs: trace: set_autosync true
01:41:43.507823857: libguestfs: trace: set_autosync = 0
01:41:43.512651238: libguestfs: trace: add_drive "/tmp/TailsToaster/TailsToasterStorage/NwpjLMFauK" "format:qcow2"
01:41:43.512776984: libguestfs: trace: add_drive = 0
01:41:43.512883682: libguestfs: trace: launch
01:41:43.513007179: libguestfs: trace: get_tmpdir
01:41:43.513098342: libguestfs: trace: get_tmpdir = "/tmp/TailsToaster"
01:41:43.513217182: libguestfs: trace: get_backend_setting "force_tcg"
01:41:43.513316827: libguestfs: trace: get_backend_setting = NULL (error)
01:41:43.513411520: libguestfs: trace: get_cachedir
01:41:43.513528431: libguestfs: trace: get_cachedir = "/tmp/TailsToaster"
01:41:43.565338843: libguestfs: trace: get_cachedir
01:41:43.565711137: libguestfs: trace: get_cachedir = "/tmp/TailsToaster"
01:41:43.565902717: libguestfs: trace: get_sockdir
01:41:43.565969436: libguestfs: trace: get_sockdir = "/tmp"
01:41:43.566229224: libguestfs: trace: get_backend_setting "gdb"
01:41:43.566357030: libguestfs: trace: get_backend_setting = NULL (error)
01:41:47.868758603: libguestfs: trace: launch = 0
01:41:47.869512646: libguestfs: trace: list_devices
01:41:47.870827404: libguestfs: trace: list_devices = ["/dev/sda"]
01:41:47.871644554: libguestfs: trace: part_disk "/dev/sda" "gpt"
01:41:47.945809047: libguestfs: trace: part_disk = 0
01:41:47.946393870: libguestfs: trace: part_set_name "/dev/sda" 1 "NwpjLMFauK"
01:41:48.001367228: libguestfs: trace: part_set_name = 0
01:41:48.002023478: libguestfs: trace: list_partitions
01:41:48.002729576: libguestfs: trace: list_partitions = ["/dev/sda1"]
01:41:48.003117944: libguestfs: trace: luks_format "/dev/sda1" "***" 0
01:41:52.131230294: libguestfs: trace: luks_format = 0
01:41:52.131559049: libguestfs: trace: luks_open "/dev/sda1" "***" "sda1_unlocked"
01:41:54.247151875: libguestfs: trace: luks_open = 0
01:41:54.247425668: libguestfs: trace: mkfs "ext4" "/dev/mapper/sda1_unlocked"
01:41:54.410542038: libguestfs: trace: mkfs = 0
01:41:54.410879741: libguestfs: trace: luks_close "/dev/mapper/sda1_unlocked"
01:41:54.437493628: libguestfs: trace: luks_close = 0
01:41:54.437756139: libguestfs: trace: close
01:41:54.437924351: libguestfs: trace: internal_autosync
01:41:54.440220688: libguestfs: trace: internal_autosync = 0
01:41:54.637244685: calling as root: test -b /dev/sda
01:41:54.809471031: call returned: [1, "", ""]
01:41:55.839856602: calling as root: test -b /dev/sda
01:41:56.165247197: call returned: [1, "", ""]
01:41:57.188903028: calling as root: test -b /dev/sda
01:41:57.537141159: call returned: [1, "", ""]
01:41:58.566594768: calling as root: test -b /dev/sda
01:41:58.955024761: call returned: [0, "", ""]
01:41:58.955271089: calling as root: mktemp -d
01:41:59.386909102: call returned: [0, "/tmp/tmp.YOBaoX1WXg\n", ""]
01:41:59.410026366: calling as root: echo asdf | cryptsetup luksOpen /dev/sda1 NwpjLMFauK_unlocked
01:42:02.488972582: call returned: [0, "", ""]
01:42:02.489307201: calling as root: mount /dev/mapper/NwpjLMFauK_unlocked /tmp/tmp.YOBaoX1WXg
01:42:03.436079164: call returned: [0, "", ""]
01:42:03.436375128: calling as root: df --output=avail '/tmp/tmp.YOBaoX1WXg'
01:42:04.002931758: call returned: [0, " Avail\n110152\n", ""]
And I plug and mount a 128 MiB USB drive with an ext4 filesystem encrypted with password "asdf" # features/step_definitions/common_steps.rb:957
01:42:04.004551920: calling as root: while echo wipe_didnt_work >> '/tmp/tmp.YOBaoX1WXg/file'; do true ; done
01:43:00.830101430: call returned: [0, "", "sh: echo: I/O error\n"]
01:43:00.830355184: calling as root: df --output=avail '/tmp/tmp.YOBaoX1WXg'
01:43:01.078934980: call returned: [0, "Avail\n 0\n", ""]
And I fill the USB drive with a known pattern # features/step_definitions/erase_memory.rb:167
01:43:01.080129116: calling as root: cat /tmp/tmp.YOBaoX1WXg/file >/dev/null
01:43:01.460394614: call returned: [0, "", ""]
And I read the content of the test FS # features/step_definitions/erase_memory.rb:174
And patterns cover at least 99% of the test FS size in the guest's memory # features/step_definitions/erase_memory.rb:178
Pattern coverage: 108.390% (113 MiB out of 105 MiB reference memory)
01:43:04.741393709: calling as root: udevadm info --device-id-of-file=/lib/live/mount/medium
01:43:04.929738609: call returned: [0, "11:0\n", ""]
01:43:04.929968532: calling as root: readlink -f /dev/block/'11:0'
01:43:05.151508539: call returned: [0, "/dev/sr0\n", ""]
01:43:05.151775979: calling as root: udevadm info --query=property --name='/dev/sr0'
01:43:05.459754556: call returned: [0, "DEVLINKS=/dev/disk/by-id/ata-QEMU_DVD-ROM_QM00005 /dev/disk/by-label/TAILS\\x203.2\\x20-\\x2020170612 /dev/cdrom /dev/disk/by-uuid/2017-06-12-18-06-31-00 /dev/disk/by-path/pci-0000:00:1f.2-ata-3 /dev/dvd\nDEVNAME=/dev/sr0\nDEVPATH=/devices/pci0000:00/0000:00:1f.2/ata3/host2/target2:0:0/2:0:0:0/block/sr0\nDEVTYPE=disk\nID_ATA=1\nID_ATA_SATA=1\nID_BUS=ata\nID_CDROM=1\nID_CDROM_DVD=1\nID_CDROM_MEDIA=1\nID_CDROM_MEDIA_DVD=1\nID_CDROM_MEDIA_SESSION_COUNT=1\nID_CDROM_MEDIA_STATE=complete\nID_CDROM_MEDIA_TRACK_COUNT=1\nID_CDROM_MEDIA_TRACK_COUNT_DATA=1\nID_CDROM_MRW=1\nID_CDROM_MRW_W=1\nID_FOR_SEAT=block-pci-0000_00_1f_2-ata-3\nID_FS_APPLICATION_ID=THE\\x20AMNESIC\\x20INCOGNITO\\x20LIVE\\x20SYSTEM\nID_FS_BOOT_SYSTEM_ID=EL\\x20TORITO\\x20SPECIFICATION\nID_FS_LABEL=TAILS_3.2_-_20170612\nID_FS_LABEL_ENC=TAILS\\x203.2\\x20-\\x2020170612\nID_FS_PUBLISHER_ID=HTTPS:\\x2f\\x2fTAILS.BOUM.ORG\\x2f\nID_FS_TYPE=iso9660\nID_FS_USAGE=filesystem\nID_FS_UUID=2017-06-12-18-06-31-00\nID_FS_UUID_ENC=2017-06-12-18-06-31-00\nID_FS_VERSION=Joliet Extension\nID_MODEL=QEMU_DVD-ROM\nID_MODEL_ENC=QEMU\\x20DVD-ROM\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\nID_PART_TABLE_TYPE=dos\nID_PART_TABLE_UUID=0000002a\nID_PATH=pci-0000:00:1f.2-ata-3\nID_PATH_TAG=pci-0000_00_1f_2-ata-3\nID_REVISION=2.5+\nID_SERIAL=QEMU_DVD-ROM_QM00005\nID_SERIAL_SHORT=QM00005\nID_TYPE=cd\nMAJOR=11\nMINOR=0\nSUBSYSTEM=block\nTAGS=:seat:systemd:uaccess:\nUSEC_INITIALIZED=6470553\n", ""]
01:43:05.460118276: calling as root: /usr/bin/eject -m
01:43:05.682666269: call returned: [0, "", ""]
When I eject the boot medium # features/step_definitions/common_steps.rb:878
And I wait for Tails to finish wiping the memory # features/step_definitions/erase_memory.rb:225
FindFailed: can not find MemoryWipeCompleted.png in S(0)[0,0 1024x768]
Line 2171, in file Region.java
(RuntimeError)
features/emergency_shutdown.feature:41:in `And I wait for Tails to finish wiping the memory'
Then I find very few patterns in the guest's memory # features/step_definitions/erase_memory.rb:213
Scenario failed at time 01:43:38Attaching the video.
#15 Updated by intrigeri 2017-07-27 18:29:51
- Subject changed from Memory erasure step is fragile with vfat or LUKS-encrypted ext4 to Memory erasure on boot medium removal is fragile with vfat or LUKS-encrypted ext4
I’ve updated the description on two of these tests runs, where the failure seem unrelated to this ticket (not sure why they pointed here, possibly a copy’n’paste issue). Other than those, all failures I see are about the “on boot medium removal” case, as expected.
#16 Updated by intrigeri 2017-07-27 19:47:24
- % Done changed from 0 to 10
- Feature Branch deleted (
bugfix/13462-vfat-LUKS-ext4-emergency-shutdown-scenarios-are-fragile) - Type of work changed from Code to Research
Interestingly, the problem was demonstrated on Jenkins only when booting from DVD. But that might mean nothing because 1. we run more emergency shutdown scenarios on DVD than on USB; 2. we run the affected scenarios (vfat, LUKS-encrypted ext4) only on DVD. However, we do exercise USB + persistent volume enabled and apparently it has never failed (yet).
The I/O errors are about the boot DVD and the SquashFS. That’s expected as all other storage devices are still available.
All the videos I’ve seen display “ModemManager is shut down” around the first line of the text console, before the I/O errors start filling the screen. I can’t find this message in the Journal on a started Tails, so I’ll assume this means that the emergency shutdown was triggered: udev_watchdog_wrapper has reached /bin/systemctl --force poweroff.
But apparently /lib/systemd/system-shutdown/tails was not run: it would display debugging info on the screen, i.e. we did not reach execute_directories(dirs, DEFAULT_TIMEOUT_USEC, arguments); in systemd’s src/core/shutdown.c yet. We use --force, so return trivial_method(argc, argv, userdata); is supposed to be run. This function connects to systemd over D-Bus,tries to talk to a polkit agent, and finally sends the PowerOff method to the org.freedesktop.systemd1.Manager D-Bus service. Given the ModemManager message mentioned above, we can conclude that we’ve reached at least that point.
So the culprit seems somewhere between the PowerOff D-Bus method call, and the time when /lib/systemd/systemd-shutdown would call /lib/systemd/system-shutdown/tails. According to the systemd doc, with --force: “When used with halt, poweroff, reboot or kexec, execute the selected operation without shutting down all units. However, all processes will be killed forcibly and all file systems are unmounted or remounted read-only”. At least the unmounting (src/core/umount.c) seems to be done by talking directly to the kernel, without exec’ing external programs.
This analysis is fine and all, but at this point I’m not sure what’s going on. Here are a few hypothesis that could be tested.
First of all, I’m not very worried about the I/O errors we see, and I’m not convinced at all they have anything to do with the problem at hand: the system is kept running, so it’s no wonder $something still tries to read stuff from the root filesystem. I’m still not sure whether there’s an actual bug in Tails, or just a robustness issue in our test suite.
This problem happens rarely, so it seems pretty clear it’s caused by a race condition. Apparently something specific to having a vfat / LUKS-encrypted ext4 filesystem mounted causes it. E.g. we do not sync after filling that USB drive with a known pattern, and when we’ll umount that filesystem during the shutdown process, the kernel has to sync it. This might take longer than the 30 seconds we wait for the “Happy dumping!” message. We could surely run sync ourselves but that would skew the results: actual users won’t do that before they trigger emergency shutdown. So let’s try to give systemd enough time to do whatever it has to do before the “Happy dumping!” message appars; in config/chroot_local-includes/usr/local/lib/initramfs-pre-shutdown-hook we wait 2 minutes after having displayed that message, so it should be safe to wait more than 30 seconds for it to appear, e.g. 90 seconds (and the remaining 30 seconds should be enough for the host system to dump the VM’s memory, and if that’s not the case we can bump that sleep 120 to whatever we need). I’ll try that.
#17 Updated by intrigeri 2017-07-30 13:28:43
- Target version changed from Tails_3.1 to Tails_3.2
#18 Updated by intrigeri 2017-09-02 09:05:05
Data points:
- In July, assuming that all July were flagged on Jenkins via
Feature #12290, and ignoring the July 12-22 period during which this test had been mistakenly disabled: this happened 4/41 times (9.8) on the stable branch and 1/27 times (3.7) on the devel branch. - In August, this happened 6/63 times (9.5) on the stable branch, 1/44 times (2.3) on the devel branch, and 28/396 times (7%) in total.
I wonder if the “happens more often on stable than on devel” tendency is statistically meaningful; whatever, we’ll see. The low occurrence rate will make it hard/costly to validate a solution, but at least I now know how many runs I’ll need to evaluate a fix.
#19 Updated by intrigeri 2017-09-02 09:11:06
- Subject changed from Memory erasure on boot medium removal is fragile with vfat or LUKS-encrypted ext4 to Memory erasure on boot medium removal is fragile
Sadly, I’ve seen this problem once in Scenario: Tails erases memory on DVD boot medium removal: aufs read-write branch in August, so making this ticket more generic.
#20 Updated by intrigeri 2017-09-02 09:18:03
- Feature Branch set to bugfix/13462-emergency-shutdown-is-fragile
intrigeri wrote:
> So let’s try to give systemd enough time to do whatever it has to do before the “Happy dumping!” message appars; in config/chroot_local-includes/usr/local/lib/initramfs-pre-shutdown-hook we wait 2 minutes after having displayed that message, so it should be safe to wait more than 30 seconds for it to appear, e.g. 90 seconds (and the remaining 30 seconds should be enough for the host system to dump the VM’s memory, and if that’s not the case we can bump that sleep 120 to whatever we need). I’ll try that.
Done locally on the topic branch, will test this heavily on my local Jenkins, adjust as needed, and once happy I’ll trigger dozens of runs on lizard.
#21 Updated by intrigeri 2017-09-03 12:04:54
- Assignee changed from intrigeri to anonym
- % Done changed from 10 to 20
- QA Check changed from Dev Needed to Ready for QA
I’ve run emergency_shutdown.feature 244 times on lizard and 306 times on my own Jenkins, against an ISO built from the topic branch, and haven’t seen any failure. FTR the failure rates observed in July + August on lizard were within the 2-10% range. So either my branch fixes the bug (that was in the test suite), or the bug (possibly in Tails) only occurs in very specific situations that didn’t arise while I was running tests. I think the only way to tell is to merge my change now, and reopen if we observe the problem again in the future (e.g. when looking at the September failures).
#22 Updated by anonym 2017-09-21 22:49:05
- Status changed from In Progress to Fix committed
- Assignee deleted (
anonym) - % Done changed from 20 to 100
- QA Check changed from Ready for QA to Pass
I didn’t do as comprehensive testing as you, but I didn’t see any regression on my system at least.
#23 Updated by anonym 2017-09-28 18:49:59
- Status changed from Fix committed to Resolved
#24 Updated by intrigeri 2019-08-30 13:08:28
- Status changed from Resolved to Confirmed
- Target version deleted (
Tails_3.2) - % Done changed from 100 to 0
- Feature Branch deleted (
bugfix/13462-emergency-shutdown-is-fragile)
The “I wait for Tails to finish wiping the memory” step failed 93 times with FindFailed: can not find MemoryWipeCompleted.png in the last 2 months:
- 27 × Tails erases memory on DVD boot medium removal: aufs read-write branch
- 22 × Tails erases memory on DVD boot medium removal: vfat
- 27 × Tails erases memory on DVD boot medium removal: LUKS-encrypted ext4
- 17 × Tails erases memory and shuts down on USB boot medium removal: persistent data
I’m going to tag these scenarios @fragile, classifying this problem as a test suite issue, as I’ve never seen this happen anywhere else.
Next step: investigate if it’s about the expected message not showing up, or showing up at a time Sikuli does not catch it, or anything else.
#25 Updated by intrigeri 2019-08-31 05:58:34
- blocks Feature #16209: Core work: Foundations Team added
#26 Updated by intrigeri 2019-08-31 05:58:51
- Priority changed from Normal to Elevated